Kano model
When trying to decide features for a product (product development), there will be some attributes that are more important than others in the face of the customers. However, it is up to the developers to find out which ones should be implemented, and in which order.
While studying it, I was constantly thinking about the close relationship with jobs theory and the 202303251644 Jobs to be done framework. What is interesting is that the Kano model does not discuss how to find the attributes customers may care about. That's left for the product designer to blindly guess (or some magic brainstorming).
There are 3 basic types of attributes (image below): - Expected: Those that if not implemented will subtract value, but if fully implemented will not add to the satisfaction. For instance, a phone with a camera is an expected attribute. (Blue line) - Performance: Those that linearly increase the satisfaction as they get better implemented. For example, battery life of a phone. (Green line) - Excitement/Attractive: Unexpected attributes that can make a difference. For example, free calls between phones. (Red line)
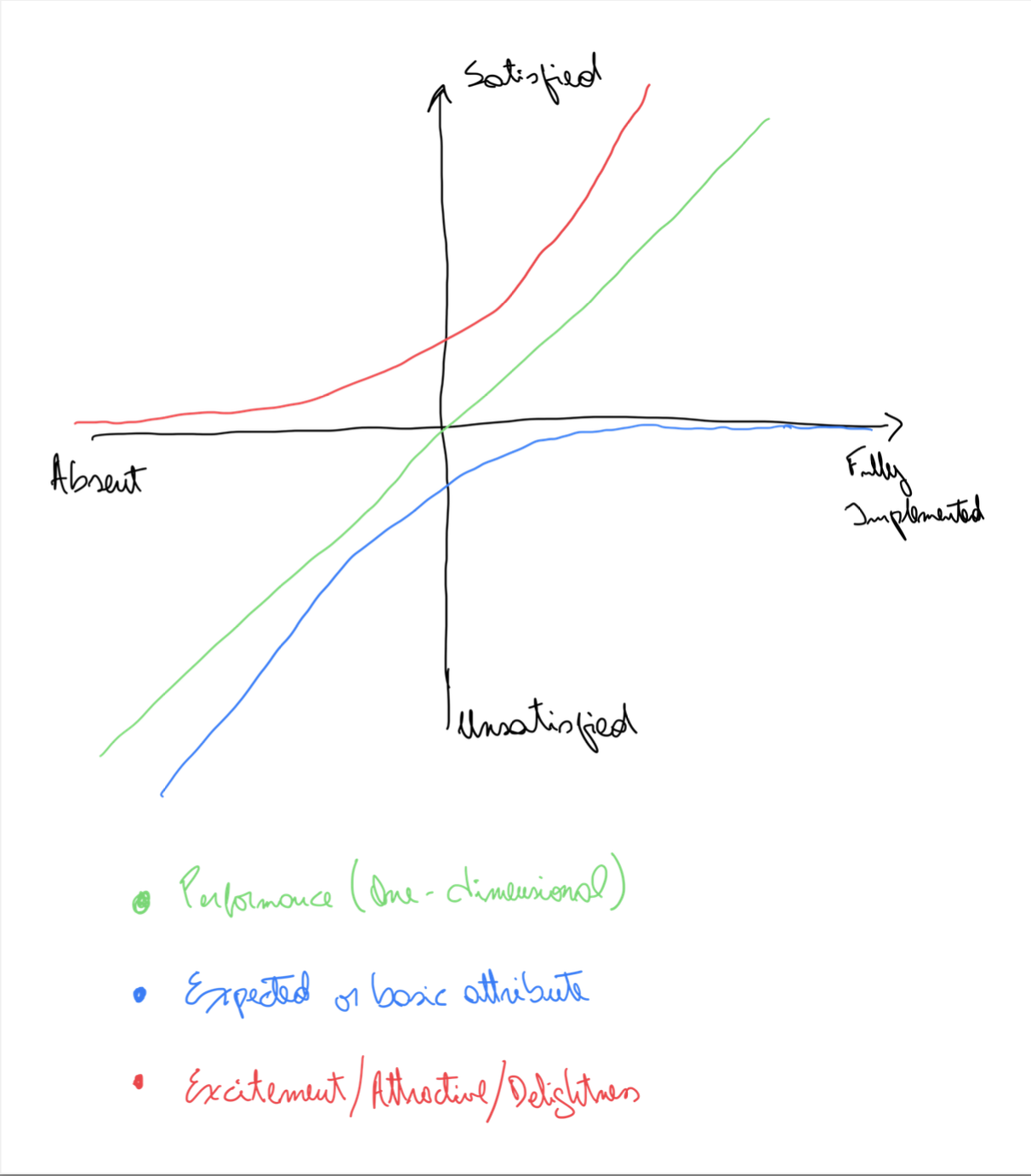
There are three more types of attributes that are not always discussed, they may seem harder to find examples, and they are harder to plot in the figure above:
- Indifference: Those that will not change the level of attractiveness whether they are available or not. For example, the available RAM on a phone (something Apple learned early on to stop using as marketing material)
- Reverse: Attributes that make it harder for the user to use the product. For example, adding layers of encryption that require to use a password every time we unlock the phone.
- Questionable: Attributes that are both attractive when they are present and their absence is also attractive. For example, location tracking: you may like the idea of knowing where you were, but you may dislike the idea of having Apple knowing where you are.
Categorizing attributes
Within the Kano Model, there is a strategy to understand how to categorize attributes. We must create a list of possible attributes and ask our users two questions per attribute: the functional and the dysfunctional:
- Functional: How do you feel if the device has a camera?
- Dysfunctional: How do you feel if the device does not have a camera?
Then, for each attribute, we can build a table like the one below:

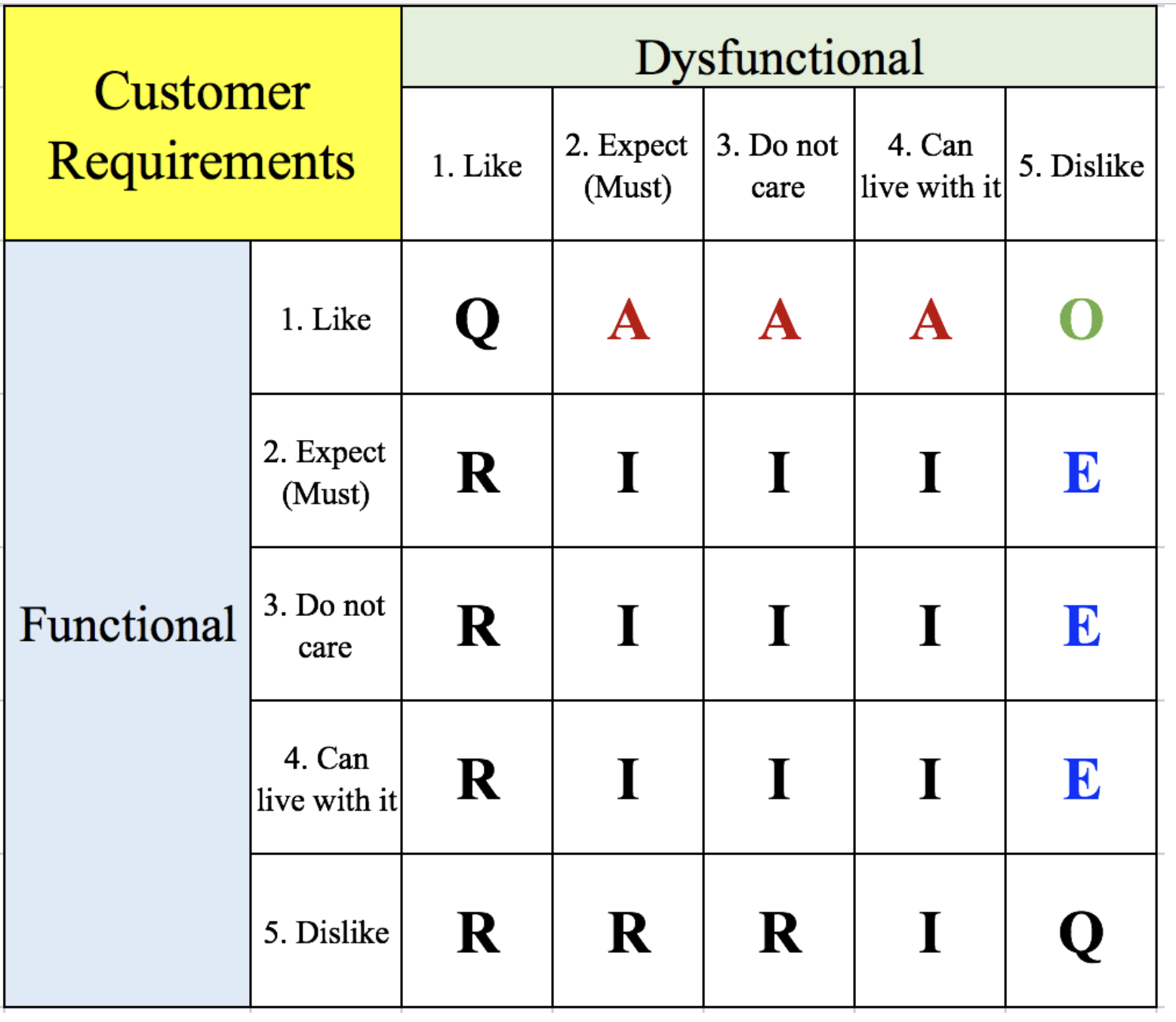
Observation: I think the table (taken from the TUM EdX course on Six Sigma) is over-dimensioned. The central 9 blocks are all "I", and on each row/column the central 3 values are always the same. I also believe the corner at the bottom left should be "O" for symmetry.
I think to lower the cognitive load on the people replying to questions, it may be better to present them with 3 options: Don't care, yes, no.
Another way to judge attributes is by looking at the following flow-chart:
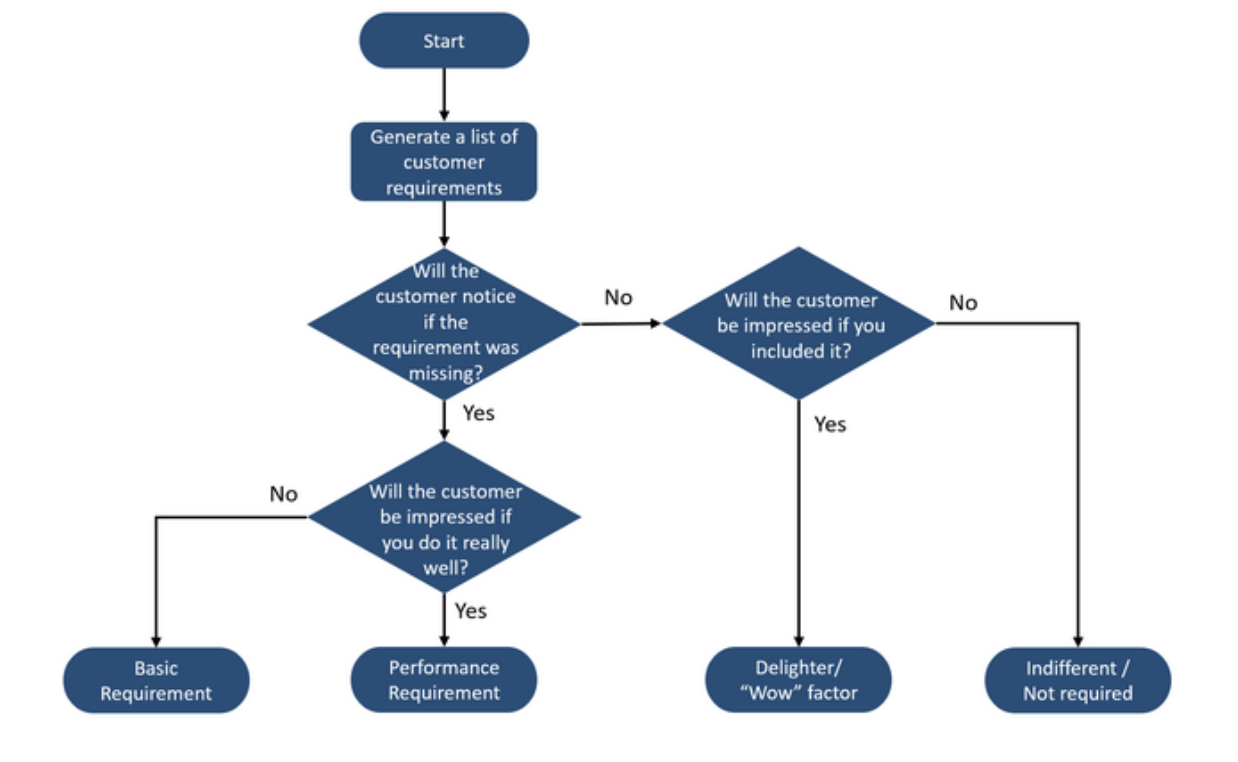
It's fundamentally the same information as the table above, but can give a clearer picture on what it means to evaluate attributes.
Interesting as it may be, as far as I've put together, the model does not say anything about prioritization of attributes.
Backlinks
These are the other notes that link to this one.
Comment
